
A General-Purpose Framework for Defining and Solving Meaningful Problems in 3 Steps.
Imagine the following scenario: your boss asks you to build a machine learning model to predict every month which customers of your subscription service will churn during the month with churn defined as no active membership for more than 31 days. You painstakingly make labels by finding historical examples of churn, brainstorm and engineer features by hand, then train and manually tune a machine learning model to make predictions.
Pleased with the metrics on the holdout testing set, you return to your boss with the results, only to be told now you must develop a different solution: one that makes predictions every two weeks with churn defined as 14 days of inactivity. Dismayed, you realize none of your previous work can be reused because it was designed for a single prediction problem.
You wrote a labeling function for a narrow definition of churn and the downstream steps in the pipeline — feature engineering and modeling — were also dependent on the initial parameters and will have to be redone. Due to hard-coding a specific set of values, you’ll have to build an entirely new pipeline to address for what is only a small change in problem definition.
Structuring the Machine Learning Process
This situation is indicative of how solving problems with machine learning is currently approached. The process is ad-hoc and requires a custom solution for each parameter set even when using the same data. The result is companies miss out on the full benefits of machine learning because they are limited to solving a small number of problems with a time-intensive approach.
A lack of standardized methodology means there is no scaffolding for solving problems with machine learning that can be quickly adapted and deployed as parameters to a problem change.
How can we improve this process? Making machine learning more accessible will require a general-purpose framework for setting up and solving problems. This framework should accommodate existing tools, be rapidly adaptable to changing parameters, applicable across different industries, and provide enough structure to give data scientists a clear path for laying out and working through meaningful problems with machine learning.
At Feature Labs, we’ve put a lot of thought into this issue and developed what we think is a better way to solve useful problems with machine learning. In the next three parts of this series, I’ll lay out how we approach framing and building machine learning solutions in a structured, repeatable manner built around the steps of prediction engineering, feature engineering, and modeling.
We’ll walk through the approach as applied in full to one use case — predicting customer churn — and see how we can adapt the solution if the parameters of the problem change. Moreover, we’ll be able to utilize existing tools — Pandas, Scikit-Learn, Featuretools — commonly used for machine learning.
The general machine learning framework is outlined below:
- Prediction Engineering: State the business need, translate into a machine learning problem, and generate labeled examples from a dataset
- Feature Engineering: Extract predictor variables — features — from the raw data for each of the labels
- Modeling: Train a machine learning model on the features, tune for the business need, and validate predictions before deploying to new data
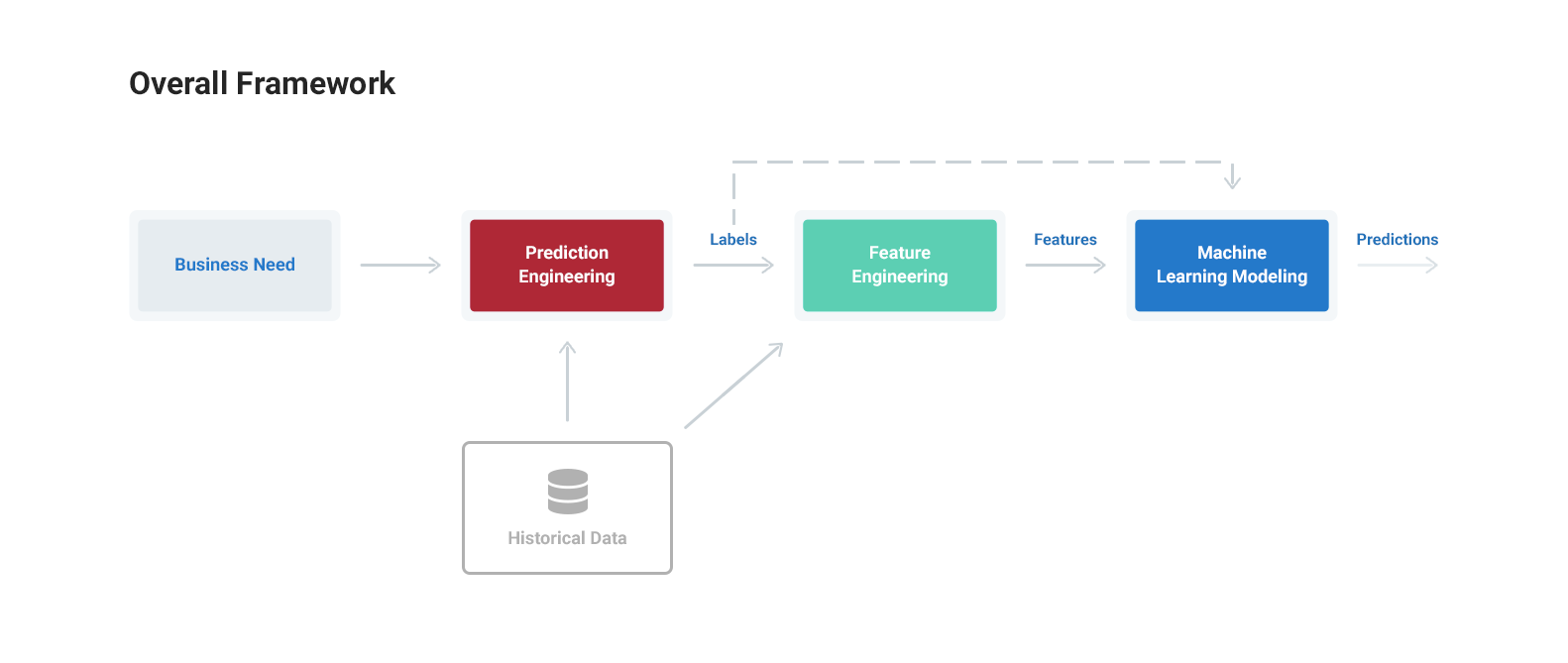
We’ll walk through the basics of each step as well as how to implement them in code. The complete project is available as Jupyter Notebooks on GitHub.
The complete set of articles is:
- Overview: A General-Purpose Machine Learning Framework (this article)
- Prediction Engineering: How to Set Up Your Machine Learning Problem
- Feature Engineering: What Powers Machine Learning
- Modeling: Teaching an Algorithm to Make Predictions
Although this project discusses only one application, the same process can be applied across industries to build useful machine learning solutions. The end deliverable is a framework you can use to solve problems with machine learning in any field, and a specific solution that could be directly applied to your own customer churn dataset.
Business Motivation: Make Sure You Solve the Right Problem
The most sophisticated machine learning pipeline will have no impact unless it creates value for a company. Therefore, the first step in framing a machine learning task is understanding the business requirement so you can determine the right problem to solve. Throughout this series, we’ll work through the common problem of addressing customer churn.
For subscription-based business models, predicting which customers will churn — stop paying for a service for a specified period of time — is crucial. Accurately predicting if and when customers will churn lets businesses engage with those who are at risk for unsubscribing or offer them reduced rates as an incentive to maintain a subscription. An effective churn prediction model allows a company to be proactive in growing the customer base.
For the customer churn problem the business need is:
increase the number of paying subscribers by reducing customer churn rates.
Traditional methods of reducing customer churn require forecasting which customers would churn with survival-analysis techniques, but, given the abundance of historical customer behavior data, this presents an ideal application of supervised machine learning.
We can address the business problem with machine learning by building a supervised algorithm that learns from past data to predict customer churn.
Stating the business goal and expressing it in terms of a machine learning-solvable task is the critical first step in the pipeline. Once we know what we want to have the model predict, we can move on to using the available data to develop and solve a supervised machine learning problem.
Next Steps
Over the next three articles, we’ll apply the prediction engineering, feature engineering, and modeling framework to solve the customer churn problem on a dataset from KKBOX, Asia’s largest subscription music streaming service.
Look for the following posts (or check out the GitHub repository):
- Prediction Engineering: How to Set Up Your Machine Learning Problem
- Feature Engineering: What Powers Machine Learning
- Modeling: Teaching an Algorithm to Make Predictions
We’ll see how to fill in the details with existing data science tools and how to change the prediction problem without rewriting the complete pipeline. By the end, we’ll have an effective model for predicting churn that is tuned to satisfy the business requirement.
Through these articles, we’ll see an approach to machine learning that lets us rapidly build solutions for multiple prediction problems. The next time your boss changes the problem parameters, you’ll be able to have a new solution up and running with only a few lines of changes to the code.
If building meaningful, high-performance predictive models is something you care about, then get in touch with us at Feature Labs. While this project was completed with the open-source Featuretools, the commercial product, offers additional tools and support for creating machine learning solutions.






